Chia ist eine Proof of Space and Time (PoST) Cryptowährung des BitTorrent Erfinder Bram Cohen. Anstatt des klassischen Minings wie bei anderen Cryptowährungen, bei denen häufig der Energieintensive Proof of Work Ansatz für den Konsensmechanismus verwendet wird (z.B. bei Bitcoin), werden beim Chia „Mining“ so genannte Plot Files berechnet, die dann später gefarmt werden um Chia Coins (XCH) zu erhalten. Dieses Farming verbraucht deutlich weniger Strom, da nur die Phase der Plot File Erstellung Energieintensiv ist. Für das spätere Farming wird nur wenig CPU Power benötigt. Daher gilt Chia als neue, grünere Alternative zu Bitcoins. Dieser Artikel soll einen kurzen Einstieg in das erstellen von Plot Files und Farming unter Windows geben.
Fallstricke und einige vorab Infos
Das Chia Netzwerk wird gerade total gehypet und wächst daher rasant. Da die Erträge beim Solofarming einer Lotterie gleichkommen, bei der die Gewinnchance steigt, je größer der eigene Speicheranteil am Gesamtnetzwerk ist, kann es aktuell schon sehr lange dauern bis du den ersten XCH Coin gefarmt hast. Dadurch wird das Solofarming immer uninteressanter wenn du nicht im sehr großen Stil einsteigen möchtest. Die kommende Pool Farming Unterstützung sorgt hier hoffentlich für gleichmäßigere und kontinuierliche Einnahmen auch für kleine Farmen. Es scheint langsam loszugehen mit dem Pool Farming. Erste Schritte kannst du mit dieser Anleitung ausprobieren.
Ein weiterer wichtiger Punkt ist die Hardware. Bevor ggf. in neue Hardware investiert wird empfiehlt es sich mit bestehender Hardware Erfahrung zu sammeln und die neue Technologie zu verstehen. Mit einem modernen Desktop PC mit 6+ Kernen, 16GB RAM, einer mindestens 300 GB großen SDD zum Plotten und einigen Terrabyte Festplatte zum Farmen ist man für den Start gut gerüstet. Das Erstellen der Plots ist auch mit einer HDD möglich, dauert aber vergleichsweise lange. Daher ist eine schnelle M2 SSD mit einem möglichst hohen TBW Wert sinnvoll. SSDs verschleißen beim Schreiben und haben damit eine begrenzte Lebenszeit. Die Total Bytes Written (TBW) geben darüber Auskunft, wie viele Daten während der Lebenszeit insgesamt auf eine SSD geschrieben werden können und eignet sich daher um zu berechnen wie viele Plots ca. mit der SSD erstellt werden können. Empfehlenswert ist z.B. die Seagate FireCuda 520 der 4ten Generation. Sie bieten laut Spezifikation einen TBW von 3600 GB.
Wer sich der Risiken und Nebenwirkungen nun bewusst ist kann gerne weiterlesen und Chia auf seinem Rechner einrichten 😉
Chia Installation und Wallet einrichten
Die Installation von Chia unter Windows ist sehr einfach. Dazu muss nur das Setup von Github heruntergeladen und ausgeführt werden. Anschließend kann über die Oberfläche ein neues Wallet in dem deine Coins gespeichert werden erstellt werden.
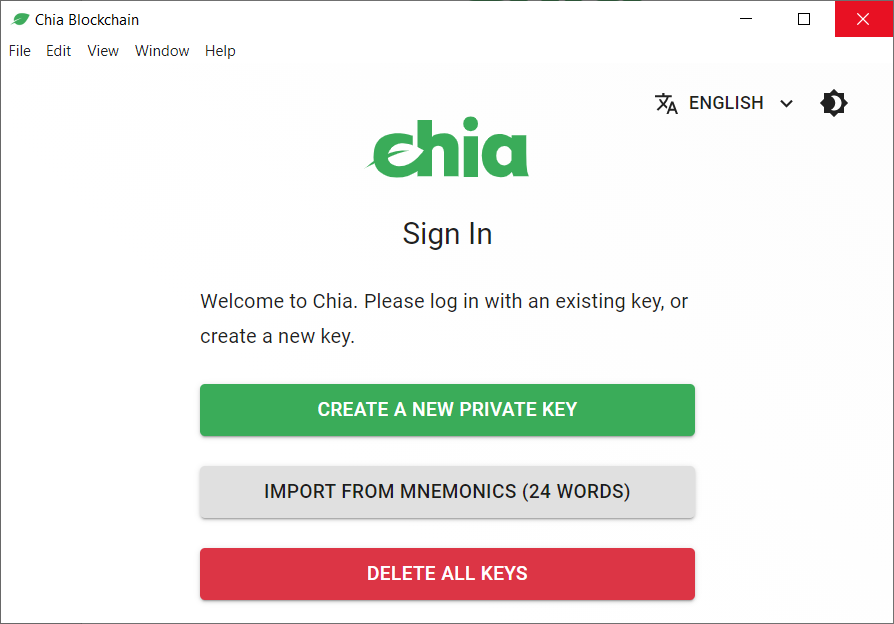
Das Programm erstellt dir für dein neues Wallet einen Mnemonic Phrase, der dir zum Wiederherstellen deines Wallet dient und auf jedenfall sicher gespeichert und geheim gehalten werden muss.
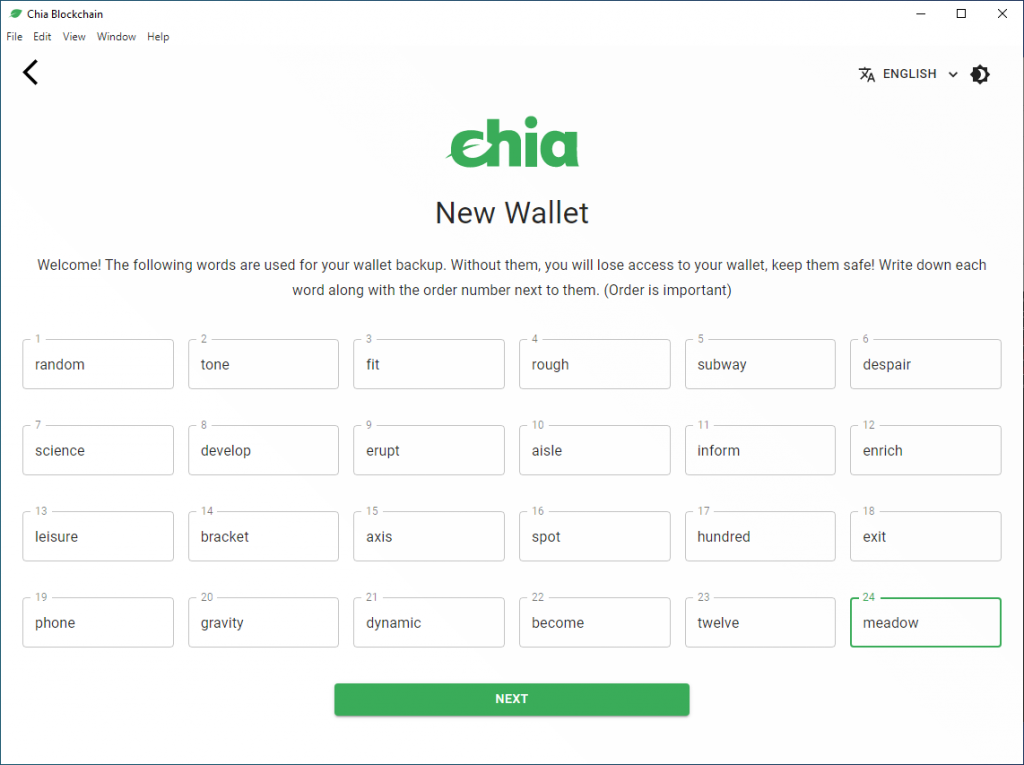
Im Anschluss findest du dich im Programm wieder. Das Programm startet automatisch einen Sync um den aktuellen Stand der Chia Blockchain zu laden.
Nicht nur der Full Node sondern auch die Wallet muss synchronisiert sein um Gewinne verbuchen und einsehen zu können oder zu farmen. Dies dauert für den ersten Sync mit einigen Stunden bis einen Tag sehr lange. Ein Resync nach einem Update geht dann deutlich schneller. Während des Synchronisierens wird zusätzlich die CPU stärker beansprucht. Der Chia Client kann aber auch jederzeit beendet werden und der Sync Vorgang später fortgeführt werden. Im nächsten Schritt wird das Erstellen von Plots beschrieben. Dies ist auch schon möglich solange der Client noch nicht vollständig synchronisiert ist.
Erstellen von Plots
Kommen wir nun zum Plotting. Hierzu links im Menü auf Plots klicken und „Add Plot“ wählen um eine oder mehrere Plot File(s) zu erstellen. Sind bereits Plot Files vorhanden, so können diese über „Add Plot Directory“ hinzugefügt werden. Generell lässt sich sagen das Erstellen von Plot Files über die Chia Software recht rudimentär ist. Möchte man diese automatisieren und besser steuern sollte auf weitere Software wie den SWAR Chia Plot Manager zurückgegriffen werden. Hier lässt sich besser einstellen wieviel Jobs parallel laufen sollen und wieviel Threads diesen zu Verfügung stehen. Ist ein Job abgearbeitet stellt der Manager automatisch einen neuen ein.
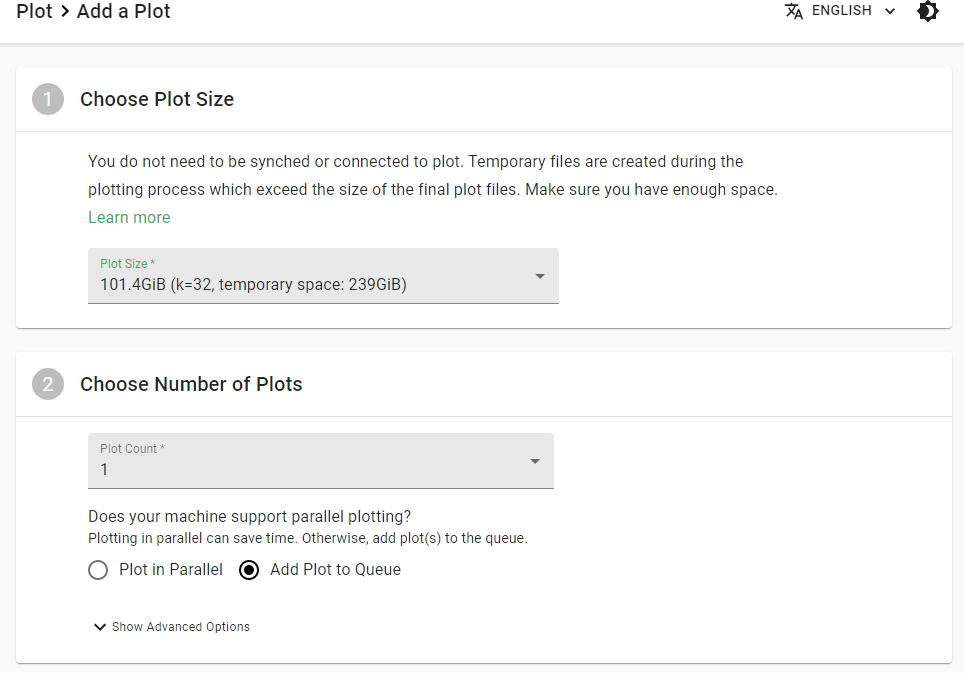
Im nachfolgenden Schritt werden die Einstellungen für die Erstellung der Plot Files durchgeführt:
Choose Plot Size:
Bei der Plot File Größe sollte der Standard bei (101,4GiB – K32) belassen werden. Größere Plot Files machen zum aktuellen Zeitpunkt keinen Sinn. Insbesondere da natürlich mehrere Plot Files dieser Größe erstellt werden können und Chia aktuell kein Pausieren der Plot File Erstellung kann. D.h. wenn ihr den PC einmal neu starten müsst, startet ihr wieder von ganz vorne und es sind womöglich viele Stunden Rechenzeit verloren.
Choose Number of Plots:
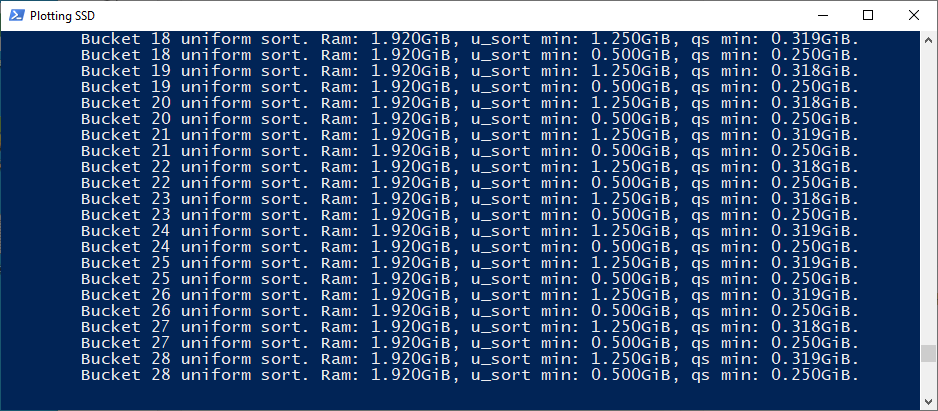
Hier kannst du die Anzahl der zu erstellenden Plots einstellen und ob diese parallel oder nacheinander erstellt werden sollen. Beachte das pro Plot Vorgang etwa 3,5GB Ram und 2 Cores benötigt benötigt werden. Wie viele Plots parallel erstellt werden können hängt damit im wesentlichen von den CPU Kernen und RAM in deinem PC ab. Die Dauer pro Plot liegt bei 6-12 Stunden je nach System. Hier heißt es dann etwas ausprobieren was die eigene Hardware schafft. Grundsätzlich lässt sich sagen, dass Plotting eine schnelle CPU, viel Arbeitsspeicher und eine schnelle Festplatte (SSD / NVMe SDD) benötigt. Achte auf jeden Fall da drauf deinem System einige Ressourcen über zu lassen.
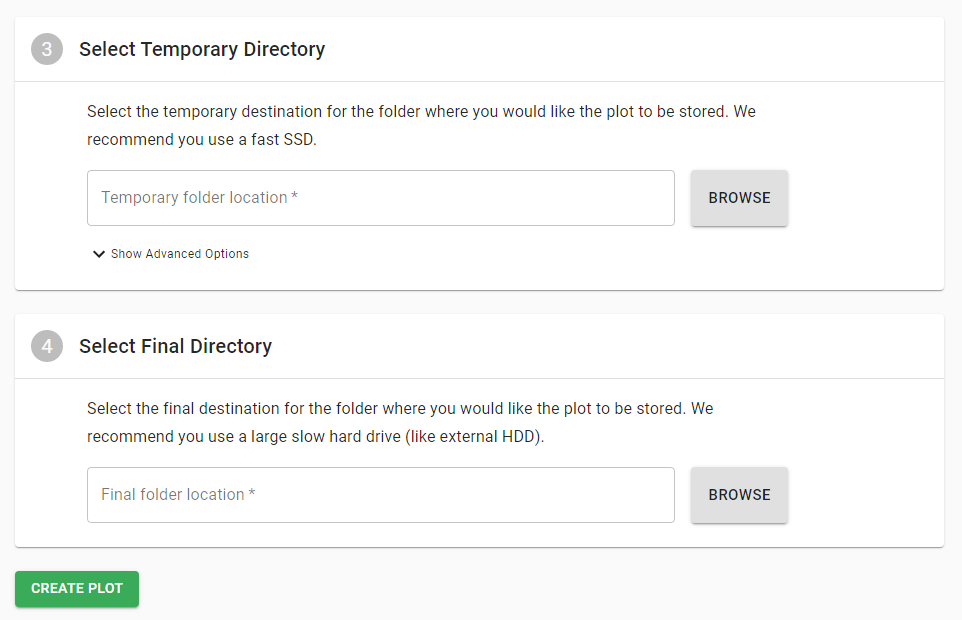
Select Temporary Directory
Das temporäre Verzeichnis wird beim Erstellen der Plot Dateien benutzt. Es sollte möglichst schnell sein und ausreichend Speicherplatz zur Verfügung stellen. Pro Plot Vorgang werden temporäre Dateien mit einer Größe von 238,3 GiB (256 GB) erstellt. Dementsprechend groß muss euer schneller Speicher dimensioniert werden. Bei vier parallelen Plots wird somit schon eine NVMe-SSD mit 1,5 TB benötigt. Die finale Plot Datei besitzt eine Größe von 101,4 GiB und sollte auf einen großen, langsamen Speicher transferiert werden, der im nächsten Schritt angegeben wird.
Select Final Directory
Dieses Verzeichnis dient dir als Lagerort für die fertigen Plot Files. Er wird für das Farming genutzt und muss nicht sonderlich schnell sein. Hier bieten sich große, günstige Festplatten an. Nachdem alles eingestellt wurde kannst du mit einem Klick auf „CREATE PLOT“ den Plot Vorgang gestartet starten.
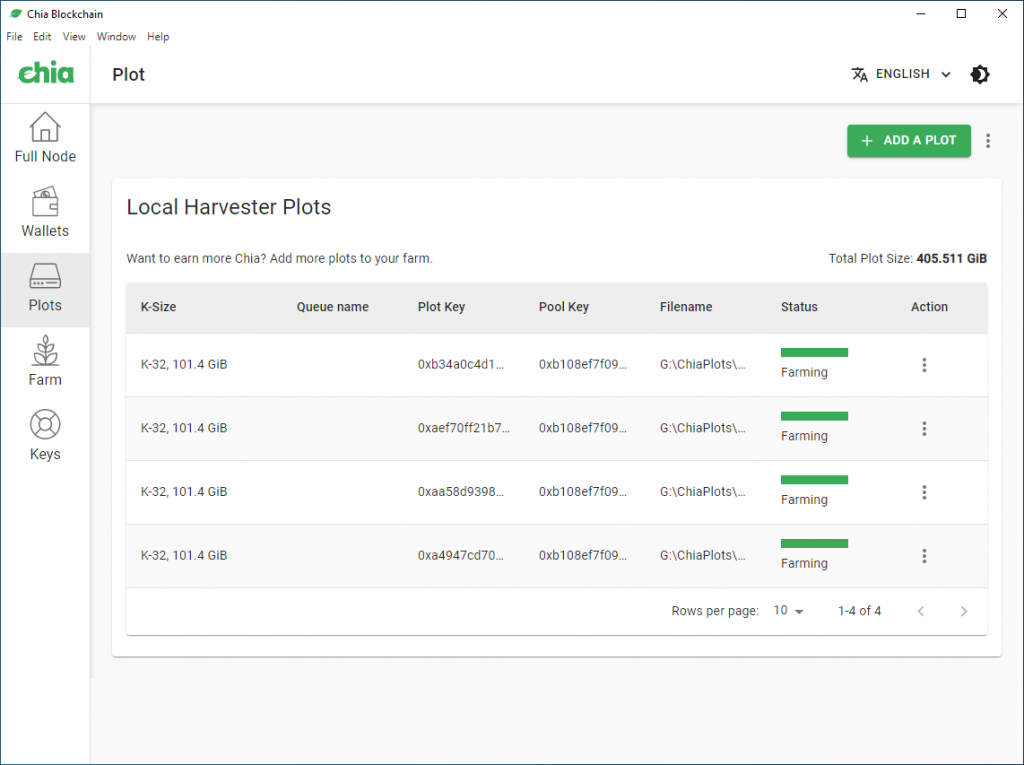
Farming
Der Farming Prozess startet automatisch sobald die Plots fertig erstellt sind und die Software vollständig mit dem Chia Netzwerk synchronisiert ist. Happy Farming!
Weitere Überlegungen zum Chia Farming
Nachfolgend einige weitere Überlegungen zum Chia Coin (XCH) Farming:
- Du kannst die Chia Blockchain Software auf mehreren Computern mit dem gleichen Schlüssel ausführen. Dazu must du nur anstatt „Create a new wallet“ “IMPORT FROM MNEMONICS (24 Words)” auswählen und deine 24 Mnemonics Wörter in der richtigen Reihenfolge eingeben.
- Die Chia Software wird schnell weiter entwickelt. Prüfe öfter ob du noch aktuell bist
- Du solltest die Chia Blockchain Software nicht zu oft Neustarten, da es bis zu einer Stunde dauern kann bis die Software wieder mit der Chia Blockchain synchronisiert ist. In dieser Zeit findet kein Farming statt.
- Die Windows Energieoptionen sollten so eingestellt werden, das Windows und vor allem nicht die Festplatten sich ausschalten.
- Wenn die Chia Software deinstalliert wird, bleibt dein Schlüssel erhalten. Um diesen zu löschen must du auf der Programmstartseite „DELETE ALL Keys“ wählen
- Aktuell erstellte Plots können nicht für das Pool Farming verwendet werden. Sobald Pools verfügbar sind und du umsteigen möchtest, macht es Sinn die alten Plots nach und nach durch Poolfähige Plots zu ersetzen und nicht alle alten Plots mit einem mal zu löschen.