Raspberry Pi mit angeschlossenem 1-Wire DS18B20 Temperatursensor
Mit dem 1-Wire Sensor
DS18B20 können mit dem Raspberry Pi einfach Temperaturen messen. Dieser Sensor verwendet das 1-Wire Bussystem zur Ãœbertragung der Daten an den Raspberry Pi und kann an die GPIO Pins angeschlossen werden. Der Sensor benutzt dabei die drei Leitungen Masse, Spannungsversorgung und eine Signalleitung. Softwareseitig bringt die Raspbian Linux Distribution bereits die benötigten 1-Wire Kernel-Module mit um solche Sensoren auszulesen. Im nachfolgenden wird gezeigt wie der Sensor an den Raspberry Pi angeschlossen wird und die Temperaturwerte ausgelesen werden können.
Hardware-Installation des DS18B20
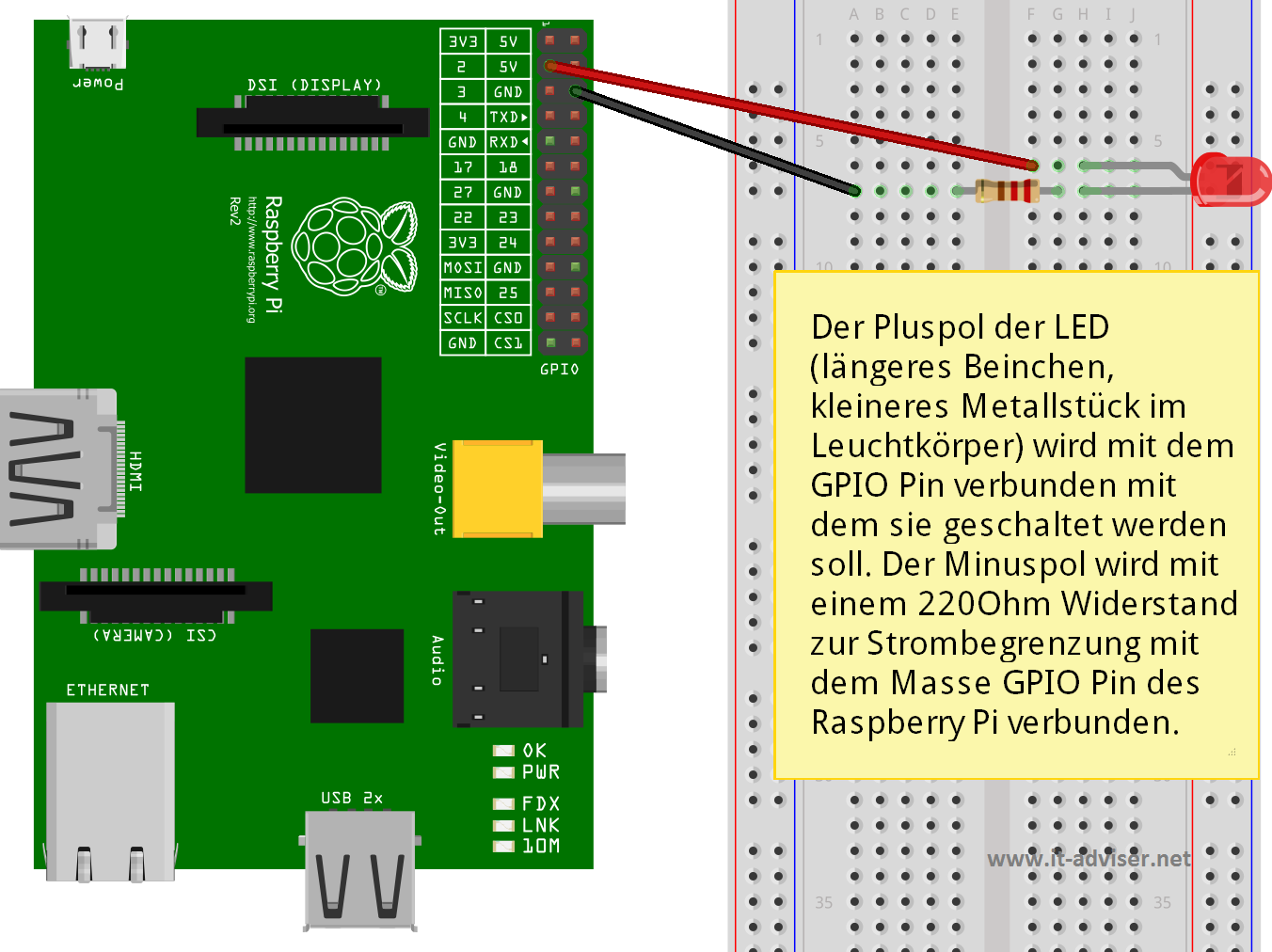
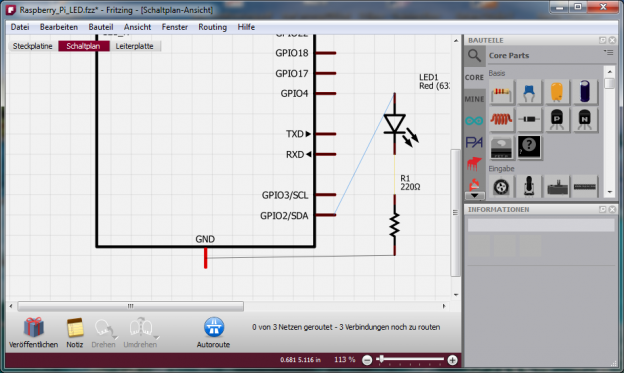
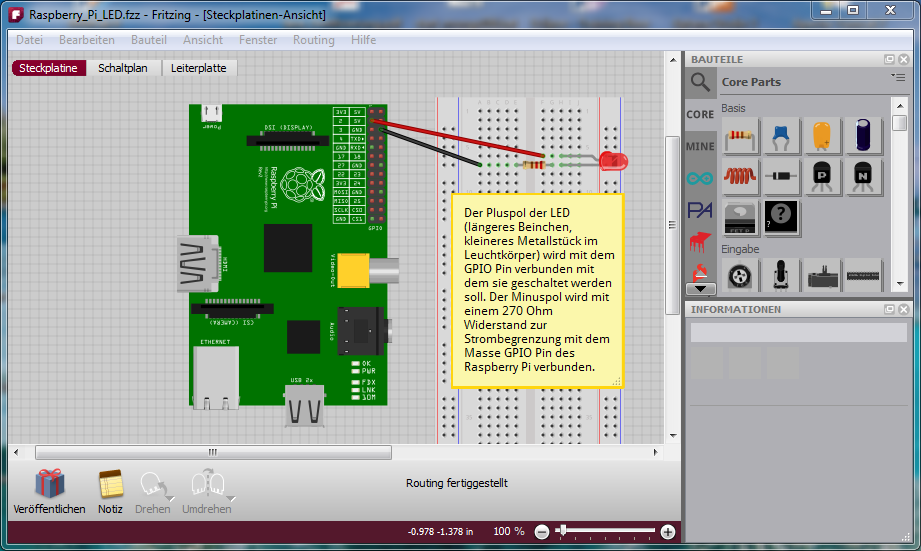
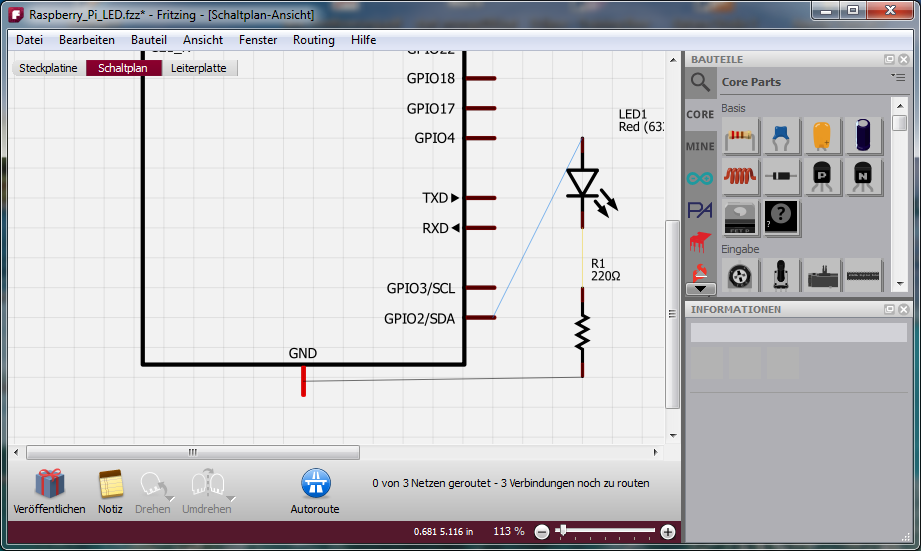
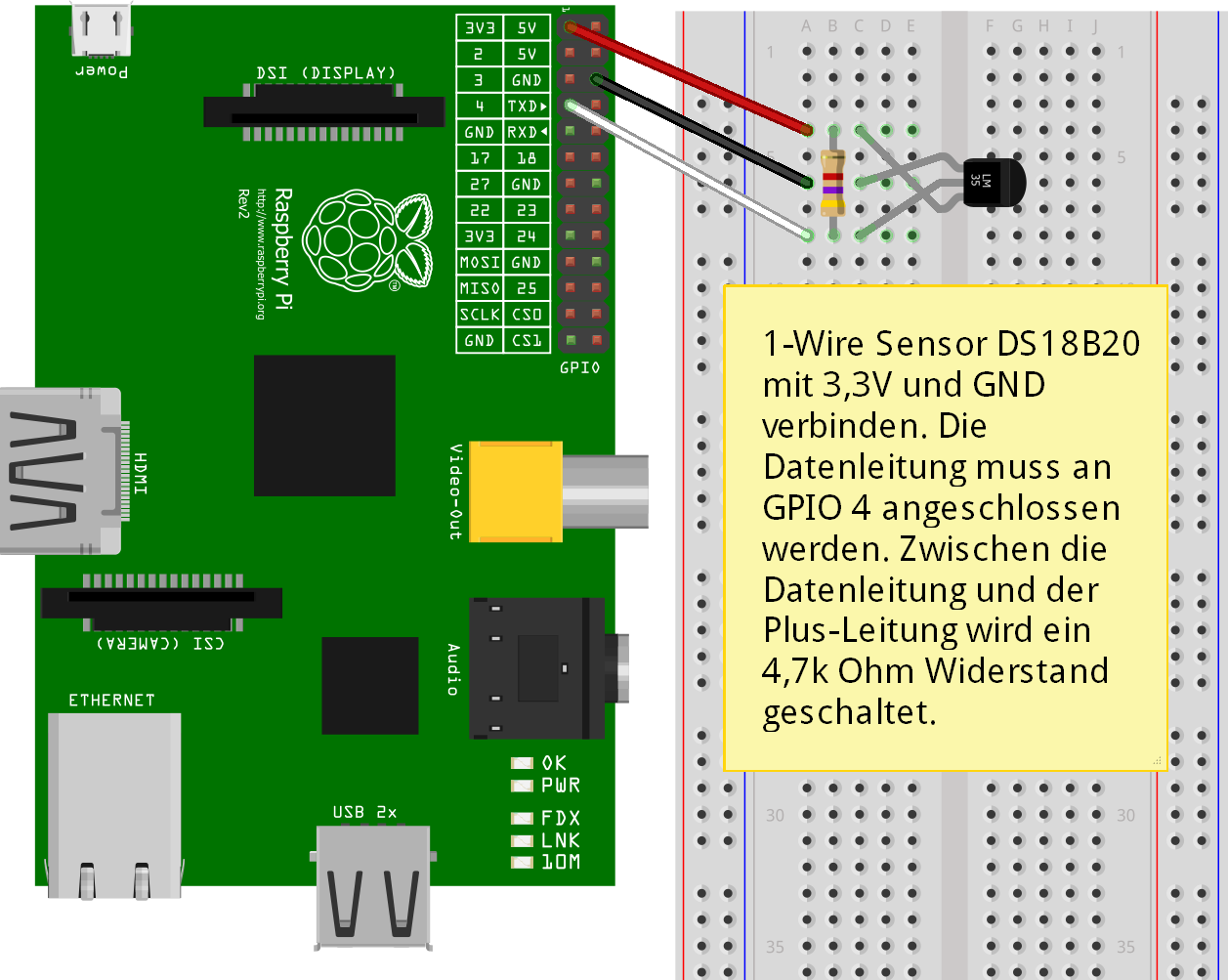
Der DS18B20 wird an die GPIO-Pins für 3,3V Spannung und Ground angeschlossen sowie an GPIO-Pin 4 für die Datenleitung. Zwischen die 5V Leitung und die Datenleitung wird 4k7 Ohm Wiederstand geschaltet. Das GPIO Pinlayout für den Raspberry Pi der Version 1 & 2 kann hier nachgeschlagen werden. Die untere Grafik zeigt den Aufbau der Schaltung:
Software-Installation des DS18B20
Die bereits angesprochenen 1-Wire Kernelmodule können mit folgendem Befehl geladen werden:
pi@raspberrypi ~ $ sudo modprobe wire
pi@raspberrypi ~ $ sudo modprobe w1_gpio
pi@raspberrypi ~ $ sudo modprobe w1_therm
Ob das Laden der Kenrel-Module erfolgreich war kann mit „lsmod“ überprüft werden:
pi@raspberrypi ~ $ sudo lsmod
Module Size Used by
w1_therm 2705 0
w1_gpio 1283 0
wire 23530 2 w1_gpio,w1_therm
cn 4649 1 wire
snd_bcm2835 12808 0
Damit die Kernel-Module nach einem Systemneustart automatisch geladen werden. Sollten sie in die Datei „/etc/modules“ eingetragen werden:
pi@raspberrypi ~ $ sudo nano /etc/modules
Module hinzufügen und speichern:
wire
w1-gpio
w1-therm
Ist die Hardware angeschlossen und die Kernel-Module geladen werden die Temperaturwerte laufend in eine Datei geschrieben. Es können mehrere Temperatursensoren angeschlossen werden, wobei jeder Sensor mit einem Verzeichnis unter „/sys/bus/w1/devices/“ auftaucht. Innerhalb des Verzeichnis eines Sensors kann die Temperatur aus der Datei „w1_slave“ ausgelesen werden. Mit dem „cat“ Befehl kann der Inhalt auf die Konsole ausgegeben werden.:
pi@raspberrypi ~ $ cat /sys/bus/w1/devices/28-00000436ccd1/w1_slave
41 01 4b 46 7f ff 0f 10 aa : crc=aa YES
41 01 4b 46 7f ff 0f 10 aa t=20062
t=20062 ist die aktuell gemessene Temperatur und entspricht 20,062 Grad.
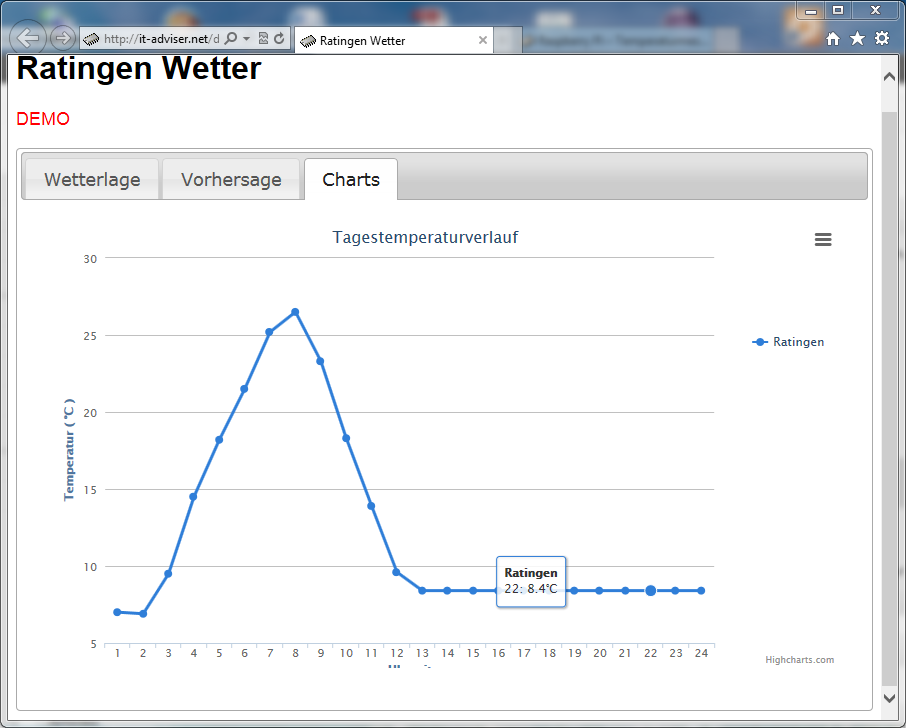
Mögliche Verarbeitung der Temperaturdaten mit PHP, MySQL Datenbank und Webseitenanzeige
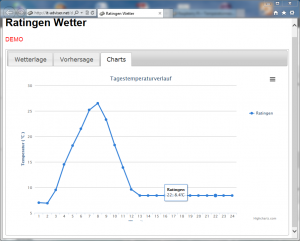 Die Temperaturwerte können auf verschiedenste Weise verarbeitet werden. z.B können sie in eine Datenbank geschrieben werden und auf einer Webseite veröffentlicht werden. Ich habe dazu ein Beispiel geschrieben, das die Temperatur im Tagesverlauf darstellt und noch einige Zusatzinformationen von Yahoo zieht. Das vorgehen wird hier nur grob beschrieben. Die benötigten Dateien sind am Ende des Artikels angefügt und können verändert werden.
Die Temperaturwerte können auf verschiedenste Weise verarbeitet werden. z.B können sie in eine Datenbank geschrieben werden und auf einer Webseite veröffentlicht werden. Ich habe dazu ein Beispiel geschrieben, das die Temperatur im Tagesverlauf darstellt und noch einige Zusatzinformationen von Yahoo zieht. Das vorgehen wird hier nur grob beschrieben. Die benötigten Dateien sind am Ende des Artikels angefügt und können verändert werden.
1. Die Temperaturwerte werden in eine Tabelle einer MySQL Datenbank geschrieben. Wie eine MySQL DB auf dem Raspi installiert wird, ist hier beschrieben.:
use DB_NAME;
CREATE TABLE TB_Weather (
timestamp BIGINT NOT NULL,
temperature FLOAT,
PRIMARY KEY (timestamp)
)
ENGINE=InnoDB;
2. Ein PHP Skript schreibt die Werte in die Tabelle. Falls der PHP Interpreter noch nicht installiert ist kann dies mit wie folgt erledigt werden. Damit kann das PHP-Skript auf der Console aufgerufen werden. „php -f temperatursensor.php“
sudo apt-get install php5
Module:
sudo apt-get install libapache2-mod-php5 libapache2-mod-perl2 php5 php5-cli php5-common php5-curl php5-dev php5-gd php5-imap php5-ldap php5-mhash php5-mysql php5-odbc
3. Mittels Cron können die Temperaturwerte zyklisch in die Datenbank geschrieben werden:
pi@raspberrypi ~ $ sudo crontab -e
In der Datei zyklisch das PHP Skript zum schreiben der Temperaturwerte aufrufrn:
*/5 * * * * php -f /home/pi/temperatursensor.php
4. Die Weboberfläche zur Auswertung der Temperaturdaten aus der DB muss auf einem Webserver wie Apache laufen und Zugriff auf die Datenbank haben.
Die Wetterinformationen werden mit dem Simple Weather Plugin von Yahoo ermittelt. Dazu muss in der index.php auf Clientseite die woeid (where on earth id) passend zu dem gewünschten Standort gesetzt werden. Die woeid kann mittels einer Suchmaschine ermittelt werden.
Download der Projektdateien zur Temperaturauswertung