Im nachfolgenden werden einige der Basistechnologien des Cloud Computing vorgestellt, um eine Wissensbasis für die nachfolgenden Kapitel zu schaffen.
Open Source
Unter Open Source fällt Software, deren Quellcode unter einer von der OSI (Open Source Initiative) anerkannten Lizenz steht und somit öffentlich verfügbar ist. Die Software kann von jedermann kostenfrei genutzt und weiterentwickelt werden.
Für das Cloud Computing von besonderer Bedeutung sind insbesondere einige größere Open Source Projekte aus den Bereichen Virtualisierung, NoSQL-Datenbanken und der verteilten Speicherung von Binärdaten, die teilweise von den Cloud Anbietern verwendet werden und an entsprechender Stelle in der Arbeit erwähnt und ggf. näher erklärt werden.
Neben der Nutzung vereinzelter Open Source Software durch die Cloud-Anbieter existieren komplette Open Source Cloud Implementierungen. Dazu zählen die Projekte Eucalyptus (Elastic Utility Computing For Linking Your Programs To Usefull Systems), OpenNebula, Open QRM und OpenStack. Das Projekt Eucalyptus ist besonders interessant, da es schnittstellenkompatibel mit den Amazon-Diensten EC2, S3 und EBS ist.
Virtualisierung
Virtualisierung ist eine der grundlegenden Technologien, die Cloud Anbieter zur Realisierung ihrer Dienste verwenden. Eine eindeutige Definition ist nicht möglich, da die Anwendungsfälle und eingesetzten Technologien im Bereich der Hard- und Software verschieden sind. Das grundlegende Ziel von Virtualisierung ist jedoch die Schaffung einer logischen Abstraktionsschicht zwischen Hardware-Ressourcen und der darauf laufenden Software, so dass die Software von der Hardware entkoppelt ist.
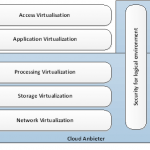
Virtualisierung kann auf verschiedenen Ebenen stattfinden, die anschaulich im nachfolgend dargestellten Modell der Kusnetzky Group beschrieben werden. Im Bereich des Cloud Computing sind die unteren drei Ebenen sowie die Security- und Management-Ebene von Bedeutung:
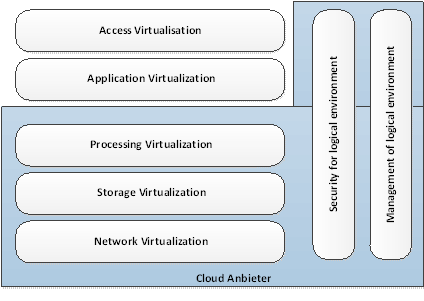
Abb. 4 Ebenen der Virtualisierung
Processing virtualization
Die Processing virtualization wird genutzt, um auf einem physikalischen Server zeitgleich mehrere Server laufen zu lassen. Um dies zu erreichen, können zwei Kategorien von Virtualisierungstechnologien eingesetzt werden. Zum einen die „Voll Virtualisierung“, bei der die komplette Hardware eines Computers virtuell nachgebildet wird und zum anderen die „Para Virtualisierung“, bei der der Kernel des Gast OS (Operating System) angepasst werden muss. Der bekannteste Vertreter der Para Virtualisierung ist das Produkt XEN, bei dem die Gast OSs direkt auf der Hardware des Host System laufen. Aus diesem Grund ist XEN extrem schnell weswegen Amazon für seine EC2-Instanzen auf diesen setzt.
Im Nachfolgenden werden die bekanntesten Hypervisor Technologien aufgelistet:
Voll Virtualisierung Hypervisor Technologien:
-
VMware (Closed Source)
-
HyperV (Closed Source)
-
QEMU (Quick Emulator, Open Source)
-
KVM (Kernel-based Virtual Machine, Open Source)
-
Virtual Box (Open Source)
Para Virtualisierung Hypervisor Technologien:
-
XEN (Open Source)
Network virtualization
Network virtualization ermöglicht durch Hard- und Software-Technologien eine logische Sicht auf das Netzwerk, die sich von dem tatsächlichen physikalischen Aufbau des Netzwerkes unterscheidet und meist zentral über eine Management Software VIM (Virtual Infrastructure Manager) gesteuert werden kann. Dadurch können auf einfache Weise Teilnetze gebildet werden, in denen Computer zu Gruppen zusammengefasst sind, die gegenseitig Daten austauschen dürfen. Eine Technik zur Bildung der Teilnetze ist VLAN (Virtual Local Area Network).
Eine weitere häufig eingesetzte Technologie ist die Bündelung mehrerer Netzwerkverbindungen zu einer logischen Verbindung. Dadurch werden die Datenübertragungsrate und die Zuverlässigkeit erhöht. Eine mögliche Technologie zur Umsetzung bietet das nach IEEE 802.3ad spezifizierte LACP (Link Aggregation Protocol).
Weitere Technologien sind NAT (Network Address Translation), Network Isolation sowie komplett virtuelle Switche in den eingesetzten Hypervisor-Produkten.
Storage virtualization
Mit Storage virtualization wird eine logische Schicht zwischen den physischen Systemen zur Datenhaltung wie SAN (Storage Area Networks) und RAID (Redundant Array of Independent Disks) und den darauf zugreifenden Servern gebildet. Anwendungen greifen auf diese Zwischenschicht zu und brauchen damit nicht mehr genau wissen, auf welcher Festplatte, Partition oder Speicher-Subsystem die Daten liegen. Das Management der Datenhaltung wird damit zentralisiert und vereinfacht. Die Kapazität lässt sich je nach Bedarf nahezu beliebig skalieren, weshalb Cloud-Anbieter diese Technologie einsetzen. Mit HDFS (Hadoop Distributes File System) existiert eine Open Source Lösung der Apache Software Foundation, die es erlaubt mehrere Petabyte an Daten über viele Speicherknoten zu verteilen.
Aspekte die für die Nutzung von Virtualisierungs €“Techniken bei Cloud-Anbietern sprechen:
-
Bessere Auslastung der Hardware-Ressourcen, da mehrere virtuelle Instanzen auf der gleichen physikalischen Hardware laufen können.
-
Verringerter Energiebedarf der Server aufgrund der besseren Auslastung
-
Geringere Hardware Kosten, da bei guter Disaster Recovery günstigere Consumer Hardware eingesetzt werden kann.
-
Schnelle Disaster Recovery bei der die MTTR (Mean Time To Recovery) deutlich gesenkt ist. Virtuelle Maschinen können häufig ohne Service-Unterbrechung im laufenden Betrieb auf andere Hosts verschoben werden.
-
Das Deployment neuer Server geht aufgrund von fertigen Server Images sehr schnell.
-
Es existiert ein zentrales Management für die virtuellen Server.
NoSQL-Datenbanken
NoSQL steht für Not only SQL und bezeichnet eine neue Art von Datenbanken, die nicht den viel genutzten relationalen Ansatz verfolgen. Es handelt sich bei ihnen um strukturierte Datenspeicher, die keine festgelegten Tabellenschemata verwenden und zumeist ohne Joins auskommen. Sie skalieren sehr gut horizontal, d.h. durch das Hinzufügen weiterer Datenbankserver und können große Datenmengen schnell verarbeiten, weshalb sie gut für das Cloud Computing geeignet sind. Die Abfrage der Daten erfolgt in einer proprietären Sprache, die jedoch häufig an SQL angelehnt ist. Zumeist werden nicht alle ACID (Atomicity, Consistency, Isolation und Durability)-Eigenschaften durch die NoSQL Datenbanken erreicht. Insbesondere wird das Prinzip der Isolation und Konsistenzhaltung nur begrenzt umgesetzt, da häufig auf Transaktionen und Normalisierung verzichtet wird.
Es haben sich vier grundlegende Formen der NoSQL Datenbanken herausgebildet:
Key-Value-Datenbank
Die meisten NoSQL-Datenbanken arbeiten als Key-Value Store. Hierbei wird ein Schlüssel verwendet, der auf einen bestimmten Wert verweist. Das Verfahren ist mit den aus der Programmierung bekannten Hash Maps oder assoziativen Arrays vergleichbar, wo über einen Namen auf den Wert zugegriffen werden kann. Jeder der in dieser Arbeit vorgestellten Cloud Computing-Anbieter bietet eine NoSQL basierte Datenbank nach dem Key-Value Prinzip an. Google BigTable, Amazon SimpleDB und Microsoft Azure Table.
Spaltenorientierte-Datenbank
Spaltenorientierte Datenbanken speichern die Daten als Schlüssel-Wert-Relation. Sie haben eine sehr hohe Performance, da aufgrund ihres Designs eine Minimierung der Festplatten I/O Aktivität vorliegt. Der bekannteste Vertreter dieser Gattung von NoSQL-Datenbanken ist Cassandra. Cassandra ist aktuell ein Top Level Projekt der Apache Foundation und wird bei den Webdiensten Facebook, Twitter und Digg verwendet.
Dokumentenorientierte Datenbank
Diese Form der NoSQL-Datenbanken speichert Textdaten beliebiger Größenordnung ab. Die Daten werden als Ganzes betrachtet und nicht weiter unterteilt. Die Datenbank nimmt eine Indexierung der Daten vor und erlaubt einen Zugriff nicht nur über den Primärschlüssel, sondern auch über die Dokumenteninhalte. Die bekanntesten Open Source Vertreter dieser Datenbank Kategorie sind CouchDB und MongoDB.
Graphen-Datenbank
Graphen-Datenbanken werden seltener eingesetzt und decken ganz spezielle Anwendungsfälle ab. Sie speichern die Beziehung zwischen Elementen in einem Graphen. Dabei kann es sich beispielsweise um ein Beziehungsgefüge in einem sozialen Netzwerk handeln. Open Source-Implementierungen sind z.B. Neo4j und FlockDB, die von dem Webdienst Twitter genutzt wird.
NoSQL-Datenbanken sind nicht für alle Anwendungsfälle geeignet. Es gilt genau abzuwägen, ob die Vorteile die Einschränkungen gegenüber traditionellen relationalen Datenbanken rechtfertigen.
Serviceorientierte Architekturen (SOA)
Serviceorientierte Architekturen stellen ein Architekturmuster dar, um Softwaresysteme für verteilte Systeme umzusetzen. Der Begriff wurde erstmalig 1996 durch das Marktforschungsunternehmen Gartner benutzt. Es existiert keine eindeutige Definition, jedoch wird häufig die Definition der OASIS (Organization for the Advancement of Structured Information Standards) aus dem Jahr 2006 zitiert:
„SOA ist ein Paradigma für die Strukturierung und Nutzung verteilter Funktionalität, die von unterschiedlichen Besitzern verantwortet wird.“
Das Unternehmen hat ein Referenz Modell zur Umsetzung von Software Architekturen nach dem SOA Konzept entwickelt. Dabei werden Services generell aus einer Geschäftssicht und einer technischen Sicht beschrieben.
Die Ziele von SOA sind:
-
Flexibilisierung bestehender Prozesse durch modularen Aufbau und Kapselung einzelner Dienste
-
Dienste können wiederverwendet werden und zeichnen sich durch klar definierte und strukturierte Interfaces aus.
-
Kommunikationsinterfaces nutzen implementations unabhängige Standards wie XML, JSON und SOAP.
-
Schnelle Anpassung der Systeme an geänderte externe Einflüsse
SOA ist für Cloud-Anwendungen interessant, da es eine etablierte Architektur zur Verknüpfung von Cloud-Resourcen zur Verfügung stellt. Es existieren klar definierte
Designrichtlinien und Handlungsempfehlungen zum Aufbau der Dienste.
Webservices REST und SOAP
Bei REST (Representational State Transfer) und SOAP (Simple Object Access Protocol) handelt es sich um essentielle Techniken für die Benutzung und zur Verfügung Stellung von Webservices. Sie ermöglichen den Informationsaustausch zwischen IT-Systemen, wobei zumeist das XML- oder JSON-Format benutzt wird. REST und SOAP stehen somit in direkter Konkurrenz zueinander. Cloud Anbieter bevorzugen in der Regel das REST Protokoll, weshalb dieses im nachfolgenden näher beschrieben wird. REST wurde mit der Dissertation von Roy Fielding in Jahr 2000 bekannt. Es gibt fünf grundlegende Punkte die einen REST Services beschreiben:,,
Adressierbarkeit
Jede verteilte Ressource hat eine eindeutige Adresse, den URI (Uniform Ressource Identifier). Zur Identifizierung der Ressource wird zumeist eine Webadresse der folgenden Form verwendet:
http(s)://host:port/pfad/abfrage?parameter#fragment
Eindeutige und klar definierte Operationen
REST verwendet einfache Operationen, die auf jeden Dienst angewandt werden können. Dabei wird auf die im HTTP spezifizierten Operationen, GET, PUT, POST, DELETE, HEAD und OPTIONS zurückgegriffen.
Repräsentationsorientiertheit
Die unter einer Adresse zur Verfügung gestellten Daten können in unterschiedlichen Formen vorliegen. Insbesondere das im nachfolgenden Kapitel vorgestellte XML und JSON Format haben sich durchgesetzt.
Zustandslose Kommunikation
REST ist ein zustandsloses Kommunikationsprotokoll, bei dem jede Nachricht alle Informationen enthält um sie zu verstehen. Jede Anfrage des Clients an den Server ist in sich geschlossen. Der Server muss daher keine Zustandsinformationen zwischen zwei Anfragen speichern. Durch die Zustandslosigkeit können Webservices gut skaliert werden.
Verwendung von Hypermedia
In REST Services können Standard-Hypermedia Elemente verwendet werden. Dazu zählen insbesondere auch Hyperlinks, die Verknüpfungen zu anderen Elementen aufbauen.
Datenaustausch-Formate XML und JSON
Die Formate XML (Extensible Markup Language) und JSON (JavaScript Object Notation) werden von Cloud-Anbietern und auch den auf Cloud-Technologie aufsetzenden Web-Anwendungen innerhalb ihrer REST und SOAP Services zum Datenaustausch genutzt. Sie verwenden Plain-Text, wodurch die übertragenen Daten von Menschen lesbar sind.
XML wurde durch das W3C (World Wide Web Consortium) spezifiziert und ist verwandt mit HTML (HyperText Markup Language). Tags zur Datendefinition können im Gegensatz zu HTML jedoch frei gewählt werden. Ãœber eine DTD (Document Type Definition) kann festgelegt werden welche Elementtypen eine XML Datei beinhalten darf und welche Werte die Attribute annehmen dürfen.
JSON stellt eine Art serialisierte Form der aus Programmiersprachen bekannten Arrays und Objekten dar. JSON reicht dabei nicht an alle Funktionen von XML heran. U.a. werden keine Schemadaten, Metadaten oder eine klare Unterscheidung zwischen Attributen und Werten durchgeführt. Gerade wegen der Einfachheit und der Möglichkeit die JSON kodierten Daten bei einer AJAX (Asynchronous JavaScript and XML) basierenden Web-GUI (Graphical User Interface) wieder in JavaObjekte zu konvertieren, wird das Format gerne für die Ãœbertragung von Daten zwischen Web-/Anwendungsservern und einer Web-GUI genutzt.